3.9 AC-3 System Description
Figure 23
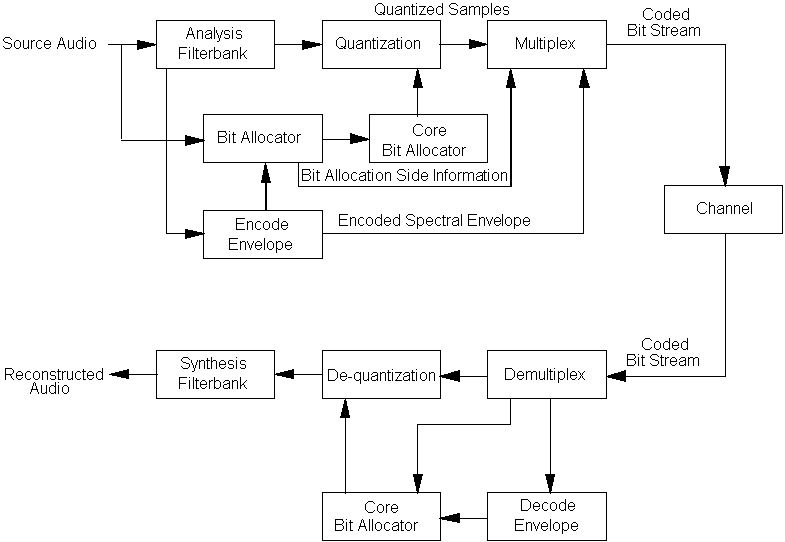
AC-3 Encoder
The AC-3 system uses a hybrid backward/forward adaptive bit allocation technique (see Fig. 24). The technique uses a core backward adaptive bit allocation routine which runs in both the encoder and decoder. The core routine is relatively simple and based on a specific psychoacoustic model. The core routine is driven by the spectral envelope and the spectral envelope information is also part of the encoded audio data delivered to the decoder. The spectral envelope and the analysis and synthesis filter banks all have the same time and frequency resolution.
The AC-3 system uses forward adaptation to enable psychoacoustic model parameter adjustment and delta bit allocation. The core bit allocation routine makes assumptions about the making properties of the signal construct and the human hearing system. Certain parameters of the model are explicitly transmitted within the bit stream. The encoder, however, can perform bit allocation based on psychoacoustic models of any complexity and compare the result to the bit allocation based on the core routine. If a better match can be made to a more ideal allocation by altering one or more of the parameters used by the core routine, the encoder can make the adjustment and inform the decoder of the change by explicitly transmitting the new parameter values. In the case where it is not possible to approach an ideal allocation by means of parameter changes, the encoder can explicitly send allocation information. The AC-3 syntax allows the encoder to send delta bit allocation information which allows the bit allocation in small frequency regions to be increased or decreased. The final bit allocation used by the encoder and the decoder must be identical and consists of the preset decoder core routine modified by the parameter changes and delta bit allocation information provided by the encoder.
The AC-3 systems uses an oddly stacked time-division aliasing cancellation (TDAC) filter bank. Overlapping blocks of 512 windowed samples are transformed into 256 frequency domain points. Audio, sampled at 48 kHz, is formed into blocks that are 10.66 ms in length, with transforms performed every 5.33 ms. A group of 6 blocks are coded into a single AC-3 frame. The blocks of 512 samples are formed from 256 new samples and 256 samples from the previous blocks. The overlapping of blocks assists in preventing audible blocking artefacts.
A proprietary 512 point Fielder window is used to achieve the best trade-off between close-in frequency selectivity and far-away rejection. The windowing operation involves vector multiplication of the 512 point audio sample block with a 512 point window function. The window function has a value of 1.0 at the centre and tapers down to near-zero at the ends. The shape of the window function results in a reconstruction free of blocking artefacts after overlap/add processing at the decoder.
The analysis filterbank is based on the Fast Fourier Transform (FFT). The TDAC transform used allows the redundancy introduced in the overlapping blocks to be removed. The input to the TDAC transform consist of 512 time domain points and results in 256 frequency domain coefficients. The frequency resolution of the filter bank is 93.75 Hz with minimum time resolution of 2.67 ms. The full resolution of the filter bank is employed except during a portion of the core bit allocation routine. Bit allocation can occur down to the individual transform coefficient level with the ability to assign different allocations to neighbouring coefficients.
The AC-3 system uses an exponent coding mechanism to reduce the amount of data necessary. First, the raw exponents of the six blocks included in a single AC-3 frame are examined for block-to-block differences. If the differences are small, a single exponent set is generated which is useable by all six blocks. If the exponents show significant differences within a frame, then exponent sets are formed over blocks where the changes are not significant. Exponents for adjacent frequencies rarely differ by more than ñ2 (1 represents a 6 dB level change) due to the nature of the frequency response of the individual filters in the analysis filter bank. Exponents are encoded differentially in frequency to take advantage of this fact. The first exponent in the block, considered the DC term, is set at its absolute value and the rest of the exponents as the difference between the current exponent and the prior exponent. The values are limited to the set +2,+1,0,-1, and -2.
Three different encoding mechanisms are employed depending upon the audio content. When fine frequency resolution is required for relatively steady signals and the spectral envelope remains relatively constant over many blocks, three differentials are encoded into a 7 bit word. This encodes each exponent into 2.33 bits and is termed D15 coding. When the spectrum is not stable, it is beneficial to send the spectral estimate more often. In order to keep the data overhead from becoming excessive two additional modes (medium and low) are used. The medium resolution mode, termed D25, transmits a delta for every other frequency coefficient resulting in a data rate of 2.33 bits per exponent pair or 1.16 bits per exponent. This mode is typically used when the spectrum is relatively stable over 2-3 audio blocks and then changes significantly. Use of the D25 mode does not allow the spectral envelope to accurately follow all of the troughs in a very tonal spectrum but does force it to follow the peaks. The final mode, termed D45, is transmitted for every four coefficients, halving again the data rate and is typically used during transients in single audio blocks. Transient signals do not typically require fine frequency resolution since by their nature they are wide band signals. The result is a transmitted spectral envelope with fine frequency resolution for relatively steady-state signals and fine time resolution for transient signals. The final coding efficiency for exponents is typically 0.39 bits per exponent (which equates to 0.39 bits per audio sample). Each coded audio block contains a 2-bit field called exponent strategy, with the four strategies being: D15, D25, D45, or REUSE. For most signal conditions, a D15 coded exponent set is sent during the first audio block in the frame and the following audio blocks reuse the same exponent set. During transient conditions, exponents are sent more often. The encoder exponent strategy may be improved over time (made extensible) and since it is explicitly encoded into the data stream, all decoders will respond to the new strategy.
The precision of the mantissas are dependent on the precision of the wordlength of the input audio source. Typically this precision is in the order of 16-20 bits, but may be as high as 24 bits. The AC-3 system quantises the normalized mantissa to a precision of between 0 and 16 bits. The number of bits allocated to each mantissa is determined by the core bit allocation routine which is identical in both the encoder and decoder. The AC-3 core bit allocation routine is considered backward adaptive in that the encoded audio information represented by the spectral envelope is fed back into the encoder and is used to compute the final bit allocation. The spectral envelope represents the power spectral density (psd) of the signal. There may be as many as 252 psd values depending upon the number of exponents sent, which is dependent on the desired audio bandwidth and sampling rate. In addition to the power spectral density, the bit allocation routine is also driven by the convolution of a spreading function matching the human hearing masking curve. The computational load is reduced by converting the psd array into smaller banded psd arrays. At low frequencies the band size is 1. At high frequencies the band size is 16. The bands increase in size proportional widening of the human ear's critical bands, and the masking curve indicates the level of quantising that can be tolerated as a function of frequency. The masking curve is subtracted from the signal spectrum in the log domain yielding the required SNR as a function of frequency. The SNR values are mapped into a set of bit allocation pointers which indicate the quantisation appropriate to each transform coefficient mantissa. The encoder counts the number of bits to determine if the bit allocation has used up the available number of bits. (All available bits are contained in a common bit pool which is available to all channels). When more bits are available, the individual mantissa SNR's may be increased until all bits are used. If too many bits have been allocated, the individual mantissa SNR's may be decreased and/or a technique termed coupling may be applied.
Within narrow frequency bands the human ear detects high frequency (above 2 kHz) localization based on the signal envelope rather than the detailed signal waveform. Direction is determined by the inter-aural time delay of the signal envelope. The ear is not able to detect the direction of two high frequency signals which are closely spaced in frequency. Coupling takes advantage of this phenomena by combining the high-frequency content of individual channels and sending the individual channel signal envelopes along the combined coupling channel. The frequency at which coupling begins is the coupling frequency. Care must be taken so that the phase of the signals to be combined does not result in cancellation. The encoder measures the signal power of the input channels in narrow frequency bands, as well as, the power in the same bands in the coupled channel. The encoder generates coupling coordinates for each individual channel which indicate the ratio of the original signal power to the coupling channel power within a band. The coupling channel is encoded in the same manner as the individual channels resulting in a spectral envelope and a set of quantised mantissas. The channels included in the coupling are sent up to the coupling frequency. Above that point, only the coupling coordinates are transmitted. The individual channel coupling coordinates are multiplied by the coupling channel coefficients in the decoder to produce the high frequency coefficients of the coupled channels. Coupling coordinates are encoded with an accuracy of <0.25 dB. Coupling should be considered a lossy process in that some of the detailed information is lost. When employed, coupling coordinates are sent in block 0 of each frame. The coupling coordinates need not be sent every block if the signal envelope is steady, but can be reused by the decoder. The encoder determines when new coupling coordinates need to be sent.
The AC-3 syntax forms a 16 bit sync word and an 8 bit word which indicates sampling rate and frame size (SI), bit stream info (BSI), the 6 transform coded audio blocks (32 ms of audio), and a 16 bit CRC error check code into an AC-3 sync frame. The BSI contains information about the number of channels coded, dialogue level, language code, and information on associated services. A 5-bit field in the BSI indicates the level of average spoken dialogue within the encoded audio program relative to the level of a full scale 1 kHz sinewave.
The system is designed such that boundaries of sync frames are appropriate for splicing of audio elementary bit streams. When bit stream splices occur randomly, frames which are incomplete will not pass the decoder's error detection test causing the decoder to mute. The decoder then enters a sync search mode. Once the sync code is found and synchronization is achieved, audio service begins again. The outage will be on the order of two frames or about 64 ms.
AC-3 syntax includes a dynamic range control word which may be encoded into each audio block allowing alteration of the reproduced audio. The control has a range of ñ 24 dB. Some broadcasters highly compress the dynamic range of the audio and fully modulate the audio channel. Sometimes the entertainment portion of the program will have a more natural dynamic range with some headroom, but the commercial messages may not. This results in significant level differences between program segments and between broadcast services. The dynamic range control word can be used in the receiver to reduce the amount of dynamic range compression introduced, allowing the listeners to control the dynamic range of the programs.
The AC-3 system uses a technique on the decoder that allows mixdown in the frequency domain. Since all channels are decoded into their frequency domain representation but not into the original time domain representation, the complexity of a 2-channel decoder, for instance, is very much reduced. The most complex portion of the algorithm, the synthesis filter bank, only has to be performed on two channels.
3.10 Ancillary Data
DTTB affords the opportunity to augment the basic video and audio service with ancillary digital data services. The flexibility of the MPEG-2 system allows new services to be easily introduced at any time in a completely backward compatible manner. Basic services include Program Subtitles, Emergency Messages, Program Guide information and Teletext.
3.10.1 Teletext
One signal source which can be regarded as data is Teletext which conforms to one of the existing systems described in ITU Recommendation BT.653. Systems A, B, C, and D contained in this specification must be capable of operating in a 50 Hz and 60 Hz environment. Because the Teletext signal is digital already it is only required to be packetised by adding a header and additional data. Fig 24 shows an example how a Teletext system for DTTB could be arranged.
3.10.2 Programme Subtitles
In any television service programme subtitles are an essential feature. There are a number of alternatives for carrying closed caption information. Possibilities include:
3.10.3 Broadcast Multimedia Services
A DTTB service has the capability of providing multimedia services such as related information services for current TV programmes, navigation services to provide easy programme selection and latest news services with multimedia and hypermedia presentation style. While the development of multimedia services in the field of computers and telecommunications has been remarkable. The coding system for the multimedia services are standardised for instance MHEG or Hyper ODA. The interoperability of the multimedia coding system with the standards is necessary to realize common receivers or LSI's. Users can view these multimedia services interactively with TV sets or home computers.
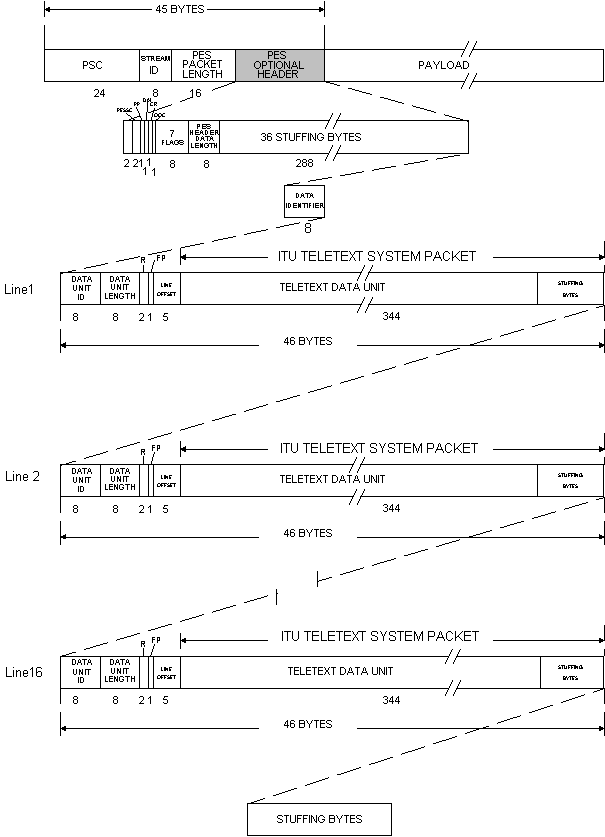
Figure 24 A Teletext Packetised Elementary Stream
Return to DTTB Tutorial Table Of Contents